

音声認識モデル【Whisper】を使ってみた~OpenAI~

スマートスケープには、先進技術の調査を行う委員会(以下:先進技術委員会)があり、社内での技術革新や新たな事業の可能性を提案するために活動しています。
先進技術委員会では、日ごろから最新技術に関する情報を収集・分析し、
それがどのように活用できるのか課題意識をもつことを大切にしています。
今回はその活動の一環で行った音声認識モデルである「Whisper」に関する調査の内容をまとめました。
その他 TECH BLOG も掲載しております!記事一覧はこちら▼
調査目的
先進技術委員会では業務における課題を考え、それを解決するシステムの開発や業務を効率化できる技術の提案を目標にしています。
そのシステムに、音声認識モデルを利用できないか検討するため、動作環境や音声認識モデルの性能比較を行うことを今回の目的としました。
音声認識とは
音声認識とは、人間の音声をコンピュータが理解し、テキストデータとして処理する技術です。この技術は身近にも利用されており、スマートフォンの音声アシスタントや翻訳ツールなど様々な場面で利用されています。
音声認識の基本的な仕組みは、入力された音声データをデジタル信号に変換し、音声モデルと照らし合わせることで言語として解釈するプロセスです。
近年、技術の発展により、音声認識の制度や速度が向上しています。
特にノイズ除去や多言語対応などの課題が克服されつつあり、様々な分野で広がりを見せています。
音声認識技術のトレンド
・ディープラーニングの進化
ディープラーニングアーキテクチャを活用した音声認識モデルが主流になっています。これにより、文脈を考慮した認識が可能になります。
・多言語対応
グローバル化にともない、複数の言語に対応できる技術が求められています。日本でも、英語モデルを元に日本語特化してトレーニングされたモデルが開発されています。
・オープンソースの普及
音声認識技術のオープンソース化が進み、誰でも利用可能な構成のモデルやツールが増えています。その中でも注目されているのがOpenAIが開発した音声認識モデルのWhisperです。
Whisperとは
Whisperとは、OpenAIが開発した高性能な音声認識モデルです。
多言語に対応されていて翻訳機能があり、ノイズ除去にも優れています。
Whisperのモデル
Whisperは複数のモデルを提供しています。
軽量性・精度の高さなど、利用シーンに応じて選択することが出来ます。
以下は其々の特徴です。

使い方
今回はGoogle ColabでWhisperを利用する方法を紹介します。
【使用ツール】Google Colaboratory
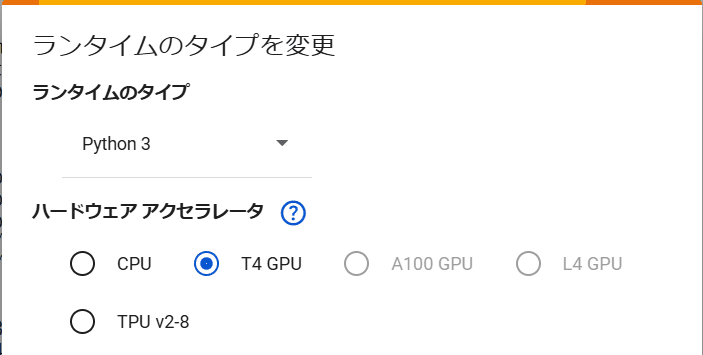
①Google Colabの設定
・ランタイムのタイプ:Python3
・ハードウェアアクセラレータ:T4 GPU
②Whisperのインストール
WhisperはPythonのライブラリとして提供されているため、以下のコマンドでインストールします。
!pip install git+https://github.com/openai/whisper.git③音声データの準備
対象の音声ファイルを用意し、GoogleColabのフォルダに追加します。
④モデルのロードと実行
以下のコードでモデルサイズを指定し、音声認識を実行します。
import whisper
model = whisper.load.model("medium")
audio = whisper.load.audio("audio.wav")
result = model.transcribe("audio,verbose=true,language="ja")
print(result["text"])⑤オプションの指定
オプションを指定することで音声を他の言語に翻訳できます。また実行結果を秒数ごとに出力するなど、出力方法も指定できます。
実行結果
今回はbaseモデル、mediumモデル、largeモデルを比較しました。黄色で塗られた部分が実際話した内容と異なる部分です。
使用音源:音声マイニングに関しての記事を読み上げた音声を使用
https://it-trend.jp/textmining/article/124-0033



baseモデル:誤りが目立ちますが、処理速度は速いです。
mediumモデル:誤字がかなり少なく、処理速度とのバランスが良いモデルだと言えます。
largeモデル:聞き取り精度は高いですが、モデルの比較表からわかる通り計算リソースが他モデルよりかなり必要になります。
どのモデルを使用するかは、求める速度や精度を考慮して選択する必要があります。
話者分離
Whisperを利用して話者分離ができるのかも試してみました。
【使用ツール】Whisper, gemini1.5pro
Whisperで文字起こしをした文章を元に、制約や出力フォーマットを指定してプロンプトを実行することで、話者分離を行うことができます。
使用音源:https://www.youtube.com/watch?v=EiAe39aAGzk



かなり正確に話者分離ができていることが分かります。
他にもpyannote.audioライブラリを使用することで話者分離をすることができます。
Whisperの最新モデル
最近発表されたWhisperのモデルを紹介します。
・whisper large-v3-turbo
Whisperのlarge-v3モデルを最適化したモデルで、精度の低下を最小限に抑えながらモデルサイズを小さくすることで処理速度を大幅に向上しています。
・kotoba-whisper
スタートアップ企業のKotoba Technologiesが開発した、日本語特化の音声認識モデルです。whisper-large-v3を最適化したモデルで、同等の精度を保ちながら約6.3倍の高速化を実現しています。また日本語に特化してトレーニングされています。
所感
今回の調査を通じて、Whisperは高精度な音声認識システムであることがわかりました。使用した音声データも、はっきり話していないものを利用したりしましたが、固有名詞などの認識力も高いと感じました。
ただ、今回は方言などの癖のある話し方でのテストはしていないので、今後そういった音声データを利用したり、リアルタイムでの音声処理なども試してみたいと思います!
We’re hiring!
スマートスケープでは一緒に働いていただける仲間を募集しています。
「こうなりたい」という思いを持ち、型にはまらず、自らの意思でキャリアを切り開ける仕組みが整っております!
ぜひお気軽に以下のフォームまたはメールアドレスにご連絡ください!
新卒採用エントリーページ
キャリア採用エントリー
またご質問等あればお気軽に下記へ連絡ください。
ss-career-recruit@smart-group.co.jp
Products
スマートスケープ株式会社
公式YouTubeチャンネル
SS4M - AIを活用した3D類似形状検索ツール
無料体験版お申し込みはこちら
QUANTO - 調達/購買業務を効率化するクラウドサービス
無料プランお申し込みはこちら
SmartExchange - 3D CADデータを3D PDF/3D HTMLに自動変換するソフトウェア
realvirtual.io - バーチャルコミッショニングを実現!